OpenAI ChatGPT 如何運作? 解構GPT-3工作原理
ChatGPT
ChatGPT作為一種 AI 語言模型,由 OpenAI 創建。OpenAI 是一個人工智能研究實驗室,專注於開發先進的 AI 技術並使它們為世界各地的人們所用。為 ChatGPT 提供支持的生成式預訓練轉換器 (GPT) 語言模型由 OpenAI 創建,作為他們對自然語言處理和機器學習正在進行的研究的一部分。GPT 和其他類似語言模型的目標是使機器能夠理解人類語言並生成與人類產生的響應相似的真實響應。

GPT
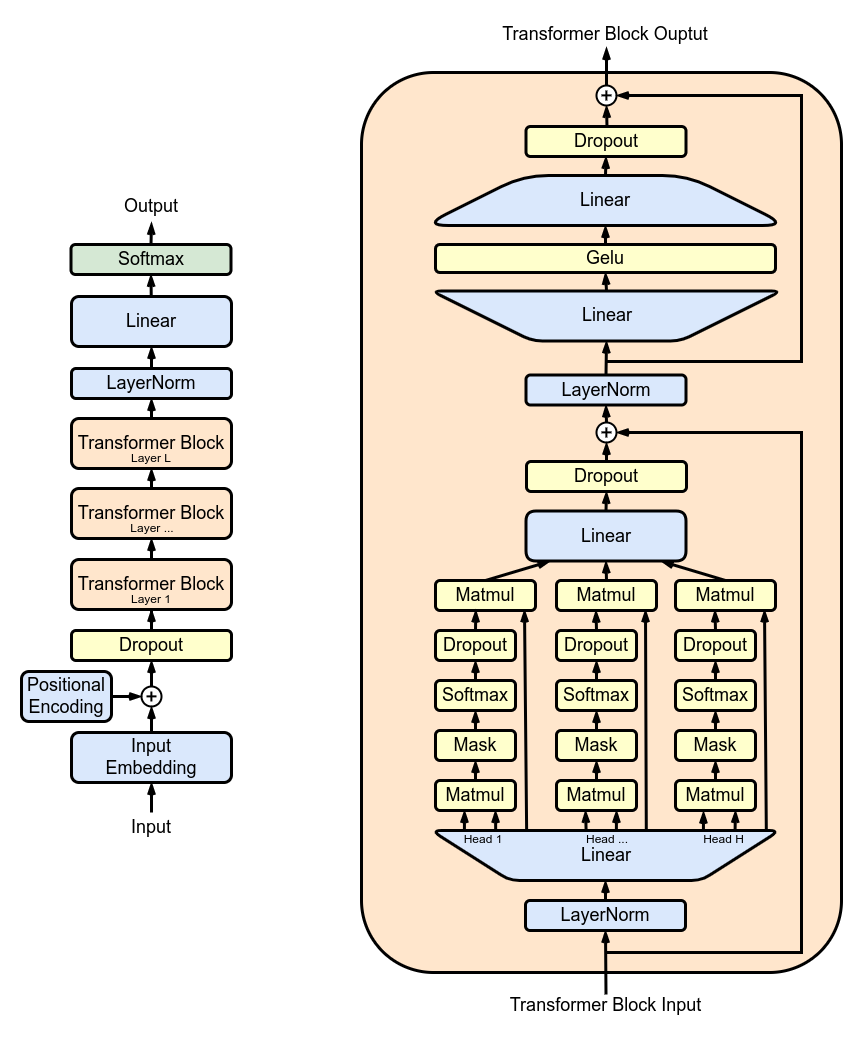
GPT是通過使用深度學習技術實現的,其基本原理是使用一個神經網絡模型來對大規模的語料庫進行預訓練,以此建立一個能夠生成自然語言的模型。具體來說,GPT使用了一種叫做Transformer的模型結構,這種結構基於自注意力機制(self-attention mechanism)來實現對語言序列的建模。
工作流程
GPT的工作原理可以概括為以下幾個步驟:

無監督學習
GPT的訓練過程中,主要使用無監督學習的方法,即不需要人工標注的數據。具體來說,GPT將輸入的語言序列分成若幹個token,然後通過多層的自注意力機制和前向神經網絡來預測每個token的下一個token。預測時,GPT會給出一個概率分布,表示每個token能夠成為下一個token的可能性大小,然後根據這個概率分布進行采樣,從而得到下一個token。通過這種方式,GPT可以不斷地生成新的文本,從而實現對自然語言的生成。
GPT的優勢
GPT的優勢在於它能夠對大規模語料庫進行預訓練,從而建立起一個通用的語言模型。這種通用性使得GPT可以應用於多種自然語言處理任務,而且只需要微調就可以適應不同的任務。此外,GPT還具備語義理解和上下文感知能力,可以識別不同單詞之間的關聯關系,從而生成更加自然的文本。
不過,GPT也存在一些缺陷,例如對於類別不平衡的數據和數據集缺乏多樣性時會出現較差的性能。此外,由於GPT是基於無監督學習的方法,因此在處理一些特定的任務時,比如問答和機器翻譯等,需要使用其他的監督學習方法進行指導。
最後總結
總之,GPT是一種基於深度學習技術的自然語言處理模型,其核心是Transformer結構和自注意力機制。它能夠對語言序列進行建模,並可以生成類人的自然語言文本,因而廣泛應用於自然語言理解和生成領域。
ChatGPT能回答提出的問題、提供信息和指導以及參與與常識、瑣事、建議和娛樂等各種主題相關的對話來幫助使用者。ChatGPT亦可以幫助完成諸如解決數學問題、提供定義、就各種主題發表意見等任務,提供有關科學、技術、歷史、娛樂等一系列主題的真實且公正的信息。還可以查找與可能感興趣的特定主題相關的資源和信息。簡而言之,ChatGPT會在編程限制範圍內盡其所能幫助使用者。如果使用者有任何問題,能夠儘管提問,它會盡力為您提供準確而有用的答覆!但是需要注意,GPT的回復是根據算法和結構化數據生成的,無法提供情感支持或專業建議。
![Python 教學 [第一章]基礎語法](/img/python-2.png)

